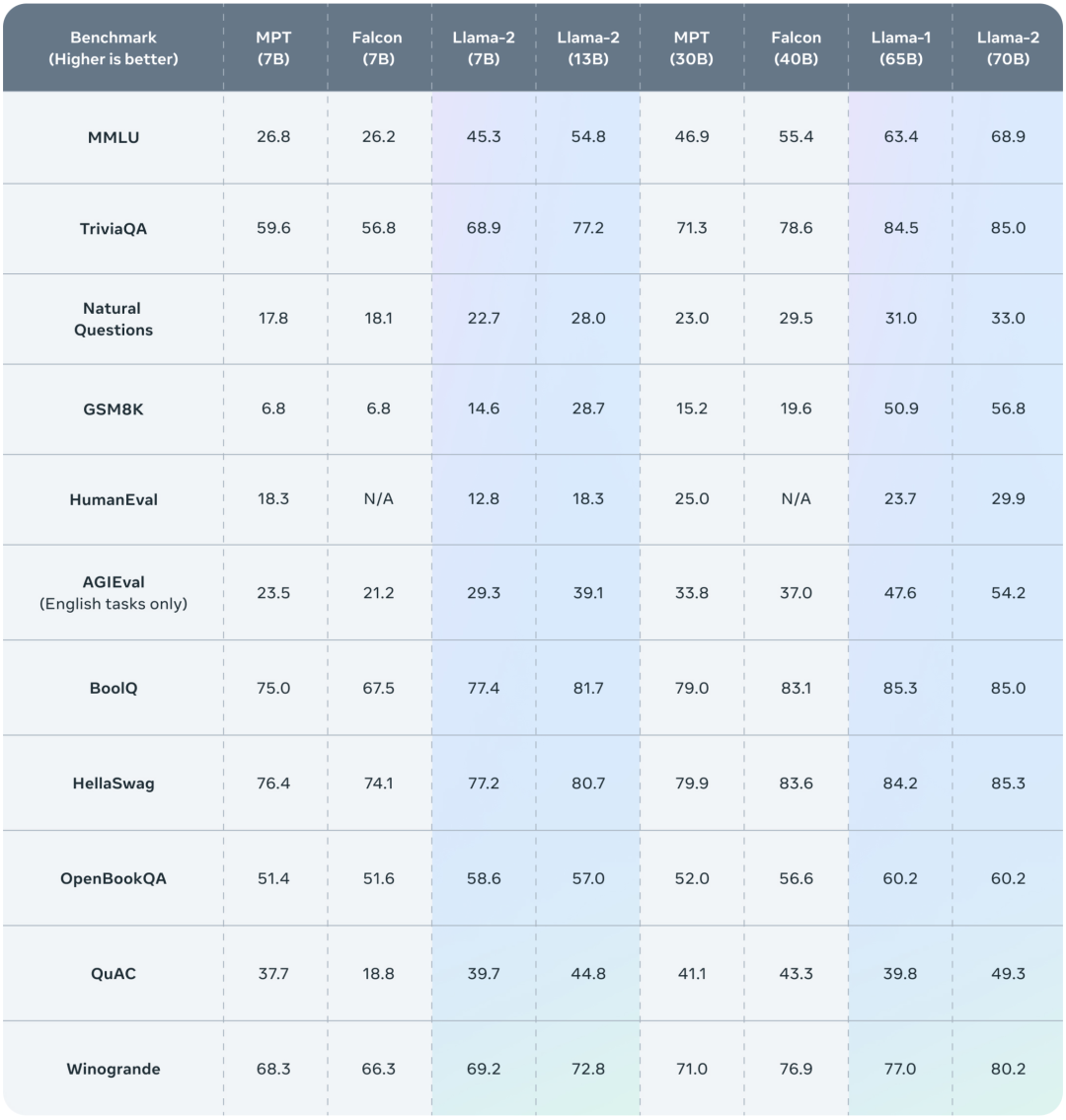
此次 Meta 发布的 Llama 2 模型系列包含 70 亿、130 亿和 700 亿三种参数变体。此外还训练了 340 亿参数变体,相比于 Llama 1,Llama 2 的训练数据多了 40%,上下文长度也翻倍,并采用了分组查询注意力机制。其预训练模型是在 2 万亿的 token 上训练的,精调 Chat 模型是在 100 万人类标记数据上训练的。公布的测评结果显示,Llama 2 在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。
论文地址:点击跳转
项目地址:https://github.com/facebookresearch/llama